Я уже писал о самых различных SQL-запросах , но пришло время поговорить и о более сложных вещах, например, SQL-запрос на выборку записей из нескольких таблиц .
Когда мы с Вами делали выборку из одной таблицы, то всё было очень просто:
SELECT названия_нужных_полей FROM название_таблицы WHERE условие_выборки
Всё очень просто и тривиально, но при выборке сразу из нескольких таблиц становится всё несколько сложнее. Одна из трудностей - это совпадение имён полей. Например, в каждой таблице есть поле id .
Давайте рассмотрим такой запрос:
SELECT * FROM table_1, table_2 WHERE table_1.id > table_2.user_id
Многим, кто не занимался подобными запросами, покажется, что всё очень просто, подумав, что здесь добавились только названия таблиц перед названиями полей. Фактически, это позволяет избежать противоречий между одинаковыми именами полей. Однако, сложность не в этом, а в алгоритме работы подобного SQL-запроса .
Алгоритм работы следующий: берётся первая запись из table_1 . Берётся id этой записи из table_1 . Дальше полностью смотрится таблица table_2 . И добавляются все записи, где значение поля user_id меньше id выбранной записи в table_1 . Таким образом, после первой итерации может появиться от 0 до бесконечного количества результирующих записей. На следующей итерации берётся следующая запись таблицы table_1 . Снова просматривается вся таблица table_2 , и вновь срабатывает условие выборки table_1.id > table_2.user_id . Все записи, удовлетворившие этому условию, добавляются в результат. На выходе может получиться огромное количество записей, во много раз превышающих суммарный размер обеих таблиц.
Если Вы поняли, как это работает после первого раза, то очень здорово, а если нет, то читайте до тех пор, пока не вникните окончательно. Если Вы это поймёте, то дальше будет проще.
Предыдущий SQL-запрос , как таковой, редко используется. Он был просто дан для объяснения алгоритма выборки из нескольких таблиц . А теперь же разберём более приземистый SQL-запрос . Допустим, у нас есть две таблицы: с товарами (есть поле owner_id , отвечающего за id владельца товара) и с пользователями (есть поле id ). Мы хотим одним SQL-запросом получить все записи, причём чтобы в каждой была информация о пользователе и его одном товаре. В следующей записи была информация о том же пользователе и следущем его товаре. Когда товары этого пользователя кончатся, то переходить к следующему пользователю. Таким образом, мы должны соединить две таблицы и получить результат, в котором каждая запись содержит информацию о пользователе и об одном его товаре .
Подобный запрос заменит 2 SQL-запроса : на выборку отдельно из таблицы с товарами и из таблицы с пользователями. Вдобавок, такой запрос сразу поставит в соответствие пользователя и его товар.
Сам же запрос очень простой (если Вы поняли предыдущий):
SELECT * FROM users, products WHERE users.id = products.owner_id
Алгоритм здесь уже несложный: берётся первая запись из таблицы users . Далее берётся её id и анализируются все записи из таблицы products , добавляя в результат те, у которых owner_id равен id из таблицы users . Таким образом, на первой итерации собираются все товары у первого пользователя. На второй итерации собираются все товары у второго пользователя и так далее.
Как видите, SQL-запросы на выборку из нескольких таблиц не самые простые, но польза от них бывает колоссальная, поэтому знать и уметь использовать подобные запросы очень желательно.
SQL - Урок 4. Выборка данных - оператор SELECT
Итак, в нашей БД forum есть три таблицы: users (пользователи), topics (темы) и posts (сообщения). И мы хотим посмотреть, какие данные в них содержатся. Для этого в SQL существует оператор SELECT . Синтаксис его использования следующий:SELECT что_выбрать FROM откуда_выбрать;
Вместо "что_выбрать" мы должны указать либо имя столбца, значения которого хотим увидеть, либо имена нескольких столбцов через запятую, либо символ звездочки (*), означающий выбор всех столбцов таблицы. Вместо "откуда_выбрать" следует указать имя таблицы.
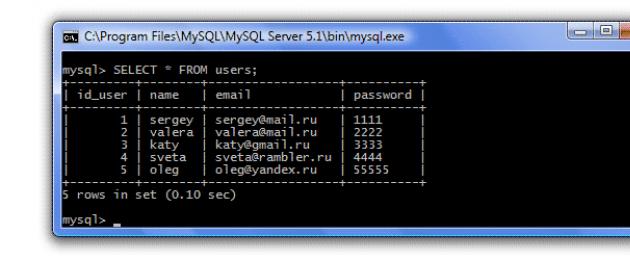
Давайте сначала посмотрим все столбцы из таблицы users:
SELECT * FROM users;

Вот и все наши данные, которые мы вносили в эту таблицу. Но предположим, что мы хотим посмотреть только столбец id_user (например, в прошлом уроке, нам надо было для заполнения таблицы topics (темы) знать, какие id_user есть в таблице users). Для этого в запросе мы укажем имя этого столбца:
SELECT id_user FROM users;

Ну, а если мы захотим посмотреть, например, имена и e-mail наших пользователей, то мы перечислим интересующие столбцы через запятую:
SELECT name, email FROM users;

Аналогично, вы можете посмотреть, какие данные содержат и другие наши таблицы. Давайте посмотрим, какие у нас существуют темы:
SELECT * FROM topics;

Сейчас у нас всего 4 темы, а если их будет 100? Хотелось бы, чтобы они выводились, например, по алфавиту. Для этого в SQL существует
ключевое слово ORDER BY
после которого указывается имя столбца по которому будет происходить сортировка.
Синтаксис следующий:
SELECT имя_столбца FROM имя_таблицы ORDER BY имя_столбца_сортировки;

По умолчанию сортировка идет по возрастанию, но это можно изменить, добавив ключевое слово DESC

Теперь наши данные отсортированы в порядке по убыванию.
Сортировку можно производить сразу по нескольким столбцам. Например, следующий запрос отсортирует данные по столбцу topic_name, и если в этом столбце будет несколько одинаковых строк, то в столбце id_author будет осуществлена сортировка по убыванию:

Сравните результат с результатом предыдущего запроса.
Очень часто нам не нужна вся информация из таблицы. Например, мы хотим узнать, какие темы были созданы пользователем sveta (id=4).
Для этого в SQL есть ключевое слово WHERE
, синтаксис у такого запроса следующий:
Для нашего примера условием является идентификатор пользователя, т.е. нам нужны только те строки, в столбце id_author которых стоит 4
(идентификатор пользователя sveta):

Или мы хотим узнать, кто создал тему "велосипеды":

Конечно, было бы удобнее, чтобы вместо id автора, выводилось его имя, но имена хранятся в другой таблице. В последующих уроках мы узнаем, как выбирать данные из нескольких таблиц. А пока узнаем, какие условия можно задавать, используя ключевое слово WHERE.
| Оператор | Описание |
| = (равно) | Отбираются значения равные указанному Пример: SELECT * FROM topics WHERE id_author=4; Результат:
|
| > (больше) | Отбираются значения больше указанного Пример: SELECT * FROM topics WHERE id_author>2; Результат:
|
| < (меньше) | Отбираются значения меньше указанного Пример: SELECT * FROM topics WHERE id_author
|
| >= (больше или равно) | Отбираются значения большие и равные указанному Пример: SELECT * FROM topics WHERE id_author>=2; Результат:
|
| <= (меньше или равно) | Отбираются значения меньшие и равные указанному Пример: SELECT * FROM topics WHERE id_author
|
| != (не равно) | Отбираются значения не равные указанному Пример: SELECT * FROM topics WHERE id_author!=1; Результат:
|
| IS NOT NULL | Отбираются строки, имеющие значения в указанном поле Пример: SELECT * FROM topics WHERE id_author IS NOT NULL; Результат:
|
| IS NULL | Отбираются строки, не имеющие значения в указанном поле Пример: SELECT * FROM topics WHERE id_author IS NULL; Результат:
|
| BETWEEN (между) | Отбираются значения, находящиеся между указанными Пример: SELECT * FROM topics WHERE id_author BETWEEN 1 AND 3; Результат:
|
| IN (значение содержится) | Отбираются значения, соответствующие указанным Пример: SELECT * FROM topics WHERE id_author IN (1, 4); Результат:
|
| NOT IN (значение не содержится) | Отбираются значения, кроме указанных Пример: SELECT * FROM topics WHERE id_author NOT IN (1, 4); Результат:
|
| LIKE (соответствие) | Отбираются значения, соответствующие образцу Пример: SELECT * FROM topics WHERE topic_name LIKE "вел%"; Результат:
|
| NOT LIKE (не соответствие) | Отбираются значения, не соответствующие образцу Пример: SELECT * FROM topics WHERE topic_name NOT LIKE "вел%"; Результат:
|







 Empty set - нет таких строк.
Empty set - нет таких строк.



 Возможные метасимволы оператора LIKE будут рассмотрены ниже.
Возможные метасимволы оператора LIKE будут рассмотрены ниже.

Метасимволы оператора LIKE
Поиск с использованием метасимволов может осуществляться только в текстовых полях.Самый распространенный метасимвол - % . Он означает любые символы. Например, если нам надо найти слова, начинающиеся с букв "вел", то мы напишем LIKE "вел%", а если мы хотим найти слова, которые содержат символы "клуб", то мы напишем LIKE "%клуб%". Например:

Еще один часто используемый метасимвол - _ . В отличие от %, который обозначает несколько или ни одного символа, нижнее подчеркивание обозначает ровно один символ. Например:

Обратите внимание на пробел между метасимволом и "рыб", если его пропустить, то запрос не сработает, т.к. метасимвол _ обозначает ровно один символ, а пробел - это тоже символ.
На сегодня достаточно. В следующем уроке мы научимся составлять запросы к двум и более таблицам. А пока попробуйте самостоятельно составить запросы к таблице posts (сообщения).
Выборка данных из таблицы в SQL осуществляется с помощью следующей конструкции:
SELECT
*|
[AS
] FROM
[WHERE
[AND
]]
[GROUP BY | [HAVING
]]
[ORDER BY
[COLLATE
]
]
Раздел SELECT
→ Определить список выходных столбцов
Список выходных столбцов может быть указан несколькими способами:
. Указать символ *, обозначающий включение в результаты запроса всех колонок запроса в естественной последовательности.
. Перечислить в желательном порядке только нужные.
Пример: SELECT * FROM Customer
→ Включить вычисляемые столбцы
В качестве вычисляемых столбцов запроса могут выступать:
. Результаты простейших арифметических выражения (+, -, /, *_ или конкатенации строк (||).
. Результаты функций агрегирования COUNT(*)|{AVG|SUM|MAX|MIN|COUNT} (
)
Примечание
: В SQL Server дополнительно можно использовать оператор % — модуль (целый остаток от деления).
→ Включить константы
В качестве столбцов могут выступать константы числового и символьного типов.
Примечание : SELECT DISTINCT ‘Для ‘, SNum, Comm*100, ‘%’, SName FROM SalesPeople
→ Переименовать выходные столбцы
Вычисляемым, а также любым другим столбцам, при желании, можно присвоить уникальное имя с помощью ключевого слова AS: AS
Примечание : В SQL SERVER дать новое имя столбцу можно с помощью оператора присвоения =
→ Указать принцип обработки дублей строк
DISTINCT – запрещает появление строк-дублей в выходном множестве. Его можно задавать один раз для оператора SELECT. На практика первоначально формируется выходное множество, упорядочивается, а затем из него удаляются повторяющиеся значения. Обычно это занимает много времени и не следует этим злоупотреблять.
ALL (действует по умолчанию) – обеспечивает включение в результаты запроса и повторяющихся значений
→ Включить агрегатные функции
Функции агрегирования (функции над множествами, статистические или базовые) предназначены для вычисления некоторых значений для заданного множества строк. Используются следующие агрегатные функции:
. AVG|SUM(|) – подсчитывает среднее значение | сумму от или, возможно без учета дублей, игнорируя NULL.
. MIN|MAX() – находит максимальное | минимальное значение.
. COUNT(*) – подсчитывает число строк во множестве с учетом NULL значений | значений в столбце, игнорируя NULL значения, возможно без дублей.
Примечания по использованию
:
. Функции агрегирования нельзя вкладывать друг в друга.
. Из-за значений NULL выражение SUM(F1)-SUN(F2)Sum(F1-F2)
. Внутри функций агрегирования допустимы выражения AVG(Comm*100)
. Если в результате запроса не получено ни одной строки или все значения равны NULL, то функция COUNT возвращает 0, а другие – NULL.
. Функции AVG и SUM могут применяться только для числовых типов, данных в Interval, а остальные могут использоваться для любых типов данных.
. Функция COUNT возвращает целое число (типа Integer), а другие наследуют типы данных обрабатываемых значений, вследствие чего следует следить за точностью результата функции SUM (возможно переполнение) и масштабом функции AVG.
Примеры на агрегатные функции:
SELECT COUNT(*) FROM Customer
. SELECT COUNT(DISTINCT SNum) FROM Orders
. SELECT MAX(Amt+Binc) FROM Orders //Если Binc – дополнительное числовое поле в Orders
. SELECT AVG(Comm*100) FROM SalesPeople //Выражение внутри функции
→ Особенности промышленных серверов
В СУБД Oracle в разделе SELECT можно указывать дополнительные указания-подсказки (hints) (27 штук), влияющие на выбор типа оптимизатора запросов и его работу.
SELECT /*+ ALL_ROWS */ FROM Orders… //наилучшая производительность
В СУБД SQL Server
:
] – задает количество или процент считываемых строк. При одинаковых последних значениях возможно считывание всех таких строк и общее число может быть больше указанного.
DECLARE @p AS Int
SELECT @p=10
SELECT TOP(@p) WITH TIES * FROM Orders
Раздел FROM
Этот раздел является обязательным и позволяет:
→ Указать имена исходных таблиц
В разделе FROM указываются имена таблиц и/или представлений, из которых будут извлекаться данные. Причем одна и та же таблица может несколько раз входить в этот раздел.
Примечание: В СУБД Oracle можно выбирать строки и из снимков (Snapshot).
→ Указать псевдонимы таблиц
Под псевдонимом таблицы понимается дополнительный, обычно краткий идентификатор, указываемый через пробел после имени таблицы/представления.
Пример: Customer C
→ Указать вариант внешнего объединения таблиц
Если в разделе FROM указано несколько таблиц, то все они неявно считаются внешними соединениями. В стандарте предусмотрены следующие основные виды соединений таблиц:
1) Перекрестное соединение
CROSS JOIN — определяются все возможные сочетания пар строк по одной для каждой строки каждой из объединяемых таблиц. Эквивалентно картезианскому соединению. Иногда называет декартовым произведением.
2) Естественное соединение
JOIN — определяются только те строки таблиц А и B, в которых значения столбцов одинаковы. Называют не совсем полноценным эквисоединением. Это автоматическое соединение по нескольким столбцам со всеми одинаковыми именами (join over).
3) Соединение объединением
UNION JOIN — определяются только те строки каждой из таблиц, для которых совпадения не были установлены. Столбцы из другой таблицы заполняются значениями NULL. Отметим, что соединение UNION и оператор UNIUN – это не одно и то же. Соединение противоположно соединению типа INNER.
4) Объединение посредством предиката
JOIN ON — фильтрует строки. Предикат может содержать подзапросы.
5) Объединение посредством имен столбцов
JOIN USING() – определяет соединение только по указанным столбцам, в то время как NATURAL – автоматически по всем одноименным.
Типы соединений
представляет собой один из аргументов: INNER
|{LEFT|RIGHT|FULL}
. INNER
– включает строки, в которых есть столбцы с совпадающими данными объединяемых таблиц. Используется по умолчанию.
. LEFT
– включает все строки таблицы А (левая таблица) и все совпадающие значения из таблицы B. Столбцы несовпадающих строки заполняются NULL-значениями.
. RIGHT
– включает все строки таблицы B (правая таблица) и все совпадающие значения таблицы А. обратный вариант для левого объединения.
. FULL
– включает все строки обеих таблиц. Столбцы совпадающих строк заполнены реальными значениями, а несовпадающих строк – NULL-значениями.
. OUTER (внешний)
– уточняющее слово, означающее, что несовпадающие строки из ведущей таблицы включаются вместе с совпадающими.
Примеры на внешнее объединение:
SELECT * FROM SalesPeople INNER JOIN Customer ON SalesPeople.City=Customer.City
. SELECT * FROM Customer LEFT OUTER JOIN SalesPeople ON SalesPeople.City=Customer.City
. SELECT * FROM Customer FULL OUTER JOIN SalesPeople ON SalesPeople.City=Customer.City
Картезианские соединения и самообъединения
. Если при включении нескольких таблиц не используются те или иные варианты соединения таблиц, то такие соединения называются картезианскими. Они используются для получения строк из двух различных таблиц. Тогда например, при соединении двух таблиц, каждая из которых содержит по 20 строк, итоговая таблица будет содержать 100 строк – каждая из строк одной таблицы с каждой из строк другой таблицы. SELECT * FROM Customer, Orders.
. Соединения одинаковых таблиц называют самообъединением (self-join).
Раздел WHERE
1. Создание внутренних соединений
Связь между таблицами осуществляют с помощью операторов сравнения, а в список выходных столбцов включают квалификационные имена для одноименных столбцов из исходных таблиц.
Основные виды соединений:
. Эквисоединения
– это соединения таблиц, основанные на равенствах. Связь между таблицами по ключевым столбцам обеспечивает ссылочную целостность. Если при соединении используются первичный и внешний ключ то всегда существует отношение «один-ко-многим» (предок/потомок).
. Тэта-соединения
– это такое соединение, когда в качестве оператора сравнения применяется неравенство (, >=, Примечания по SQL Server
В SQL Server левое, правое и полное соединение можно задать в разделе WHERE с помощью [*]=[*]. Фактически реализуется внешнее соединение, которое у других СУБД реализуется в разделе FROM.
Примеры внутренних соединений
SELECT C.CName, S.SName, S.City FROM SalesPeople S, Customer C WHERE S.City=C.City
SELECT SName, CName FROM SalesPeople, Customer WHERE SName
2. Фильтрация строк выходного множества
Раздел WHERE позволяет также определить, т.е. логическое условие, которое может быть либо истинным, либо ложным. Кроме того, одно или оба сравниваемых значения в предикате могут быть равны NULL, тогда результат сравнения может быть равен UNKNOWN. Оператор SELECT извлекает только те строки из таблиц, для которых имеет значение TRUE, исключая строки, для которых он равен FALSE или UNKNOWN.
Раздел 4 Информационные системы
Введение в SQL.
Создание, изменение и удаление таблиц.
Выборка данных из таблицы.
Создание SQL-запросов.
Обработка данных в SQL.
Методика обучения данной теме в школе.
Введение в SQL. SQL - структурированный язык запросов, который дает возможность создавать и работать в реляционных базах данных, которые являются наборами связанной информации сохраняемой в таблицах. Язык ориентирован на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц-отношений. Важнейшая особенность структур этого языка состоит в ориентации на конечный рез-тат обработки данных, а не на процедуру этой обработки. SQL сам определяет, где находятся данные, индексы и даже какие наиболее эффективные последовательности операций следует использовать для получения рез-та.
Изначально, SQL был основным способом работы пользователя с базой данных и позволял выполнять следующий набор операций: создание в базе данных новой таблицы; добавление в таблицу новых записей; изменение записей; удаление записей; выборка записей из одной или нескольких таблиц (в соответствии с заданным условием); изменение структур таблиц.
Со временем SQL обеспечил возможность описания и управления новыми хранимыми объектами (например, индексы, представления, триггеры и хранимые процедуры). SQL остаётся единственным механизмом связи между прикладным программным обеспечением и базой данных. В то же время, современные СУБД, а, также, информационные системы, использующие СУБД, предоставляют пользователю развитые средства визуального построения запросов. Каждое предложение SQL - это либо запрос данных из базы, либо обращение к базе данных, которое приводит к изменению данных в базе.
В соответствии с тем, какие изменения происходят в базе данных, различают следующие типы запросов: на создание или изменение в базе данных новых или существующих объектов; на получение данных; на добавление новых данных (записей); на удаление данных; обращения к СУБД.
Основным объектом хранения реляционной базы данных является таблица, поэтому все SQL-запросы - это операции над таблицами. В соответствии с этим, запросы делятся на:
Запросы, оперирующие самими таблицами (создание и изменение таблиц);
Запросы, оперирующие с отдельными записями (или строками таблиц) или наборами записей.
Каждая таблица описывается в виде перечисления своих полей (столбцов таблицы) с указанием: типа хранимых в каждом поле значений; связей между таблицами (задание первичных и вторичных ключей); информации, необходимой для построения индексов.
Таким образом, использование SQL сводится, по сути, к формированию всевозможных выборок строк и совершению операций над всеми записями, входящими в набор.
Команды SQL разделяются на следующие группы:
1. Команды языка определения данных - DDL (Data Definition Language). Эти SQL команды можно использовать для создания, изменения и удаления различных объектов базы данных.
2. Команды языка управления данными - DCL (Data Control Language). С помощью этих SQL команд можно управлять доступом пользователей к базе данных и использовать конкретные данные (таблицы, представления и т.д.).
3. Команды языка управления транзакциями - TCL (Тгаnsасtiоn Соntrol Language). Эти SQL команды позволяют определить исход транзакции.
4. Команды языка манипулирования данными - DML (Data Manipulation Language). Эти SQL команды позволяют пользователю перемещать данные в базу данных и из нее.
Операторы SQL делятся на:
Операторы определения данных (Data Definition Language, DDL )
CREATE создает объект БД (саму базу, таблицу, представление, пользователя и т. д.)
ALTER изменяет объект
DROP удаляет объект
Операторы манипуляции данными (Data Manipulation Language, DML )
SELECT считывает данные, удовлетворяющие заданным условиям
INSERT добавляет новые данные
UPDATE изменяет существующие данные
DELETE удаляет данные
Операторы определения доступа к данным (Data Control Language, DCL )
GRANT предоставляет пользователю (группе) разрешения на определенные операции с объектом
REVOKE отзывает ранее выданные разрешения
DENY задает запрет, имеющий приоритет над разрешением
Операторы управления транзакциями (Transaction Control Language, TCL )
COMMIT применяет транзакцию.
ROLLBACK откатывает все изменения, сделанные в контексте текущей транзакции.
SAVEPOINT делит транзакцию на более мелкие участки.
Преимущества: 1.Независимость от конкретной СУБД (тексты SQL-запросов, содержащие DDL и DML, могут быть достаточно легко перенесены из одной СУБД в другую). 2. Наличие стандартов (наличие стандартов и набора тестов для выявления совместимости и соответствия конкретной реализации SQL общепринятому стандарту только способствует «стабилизации» языка). 3. Декларативность (с помощью SQL программист описывает только то, какие данные нужно извлечь или модифицировать)
Недостатки: 1.Несоответствие реляционной модели данных 2.Повторяющиеся строки 3. Неопределённые значения (nulls) 4. Явное указание порядка колонок слева направо 5. Колонки без имени и дублирующиеся имена колонок 6. Отсутствие поддержки свойства «=» 7. Использование указателей 8. Высокая избыточность
2.2 Создание, изменение и удаление таблиц.
Создание таблицы:
Таблицы создаются командой CREATE TABLE. Эта команда создает пустую таблицу - таблицу без строк. Значения вводятся с помощью DML команды INSERT. Команда CREATE TABLE в основном определяет им таблицы, в виде описания набора имен столбцов указанных в определенном порядке. Она также определяет типы данных и размеры столбцов. Каждая таблица должна иметь по крайней мере один столбец.
Синтаксис команды:
CREATE TABLE
(
Изменение таблицы:
Команда ALTER TABLE – это содержательна форма, хотя ее возможности несколько ограничены. Она используется чтобы изменить определение существующей таблицы. Обычно, она добавляет столбцы к таблице. Иногда она может удалять столбцы или изменять их размеры, а также в некоторых программах добавлять или удалять ограничения. Типичный синтаксис чтобы добавить столбец к таблице:
ALTER TABLE